一、主旨
使用ML来支撑业务系统并不像看上去那么速赢(quick win),它往往会带来高昂的后期维护开销。本文旨在警示ML从业者(increase the community’s awareness),从技术负债的角度,论述了在做ML系统设计时需要注意的容易产生负债的几个方面:系统边界、耦合、反馈循环、消费者、数据依赖、配置问题等等。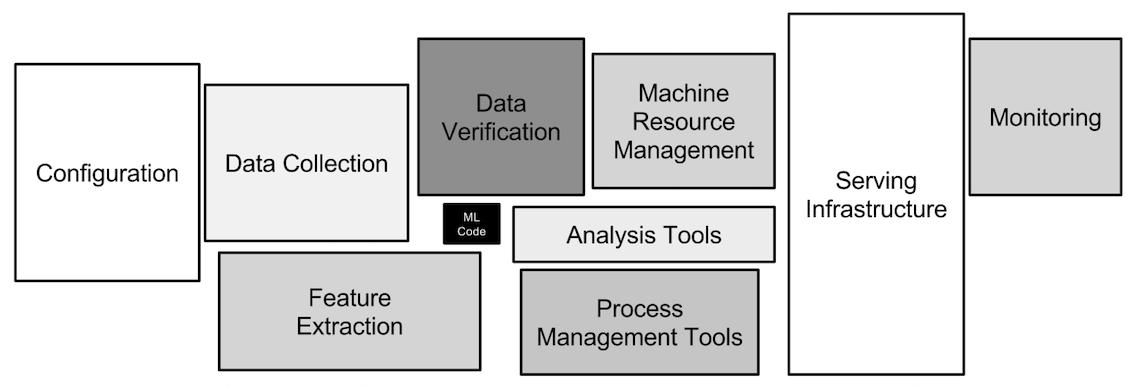
二、内容
三、Key takeaways
令人不安的趋势:开发和部署ML系统很快很便宜,但后期维护它们既难且贵
[…] a wide-spread and uncomfortable trend […] : developing and deploying ML systems is relatively fast and cheap, but maintaining them over time is difficult and expensive.
并非所有负债都是不好的,但所有负债都要支付利息/都有代价;偿还技术负债的方式有很多,例如重构,其目的不在于增加新功能,而是在于使后续优化成为可能、减少错误、增强可维护性
Not all debt is bad, but all debt needs to be serviced.
Technical debt may be paid down by refactoring code, improving unit tests, […]. The goal is not to add new functionality, but to enable future improvements, reduce errors, and improve maintainability.
在系统设计时考虑技术负债能够提前认识到加速工程落地会为系统维护带来的长期开销
[…] help reason about the long term costs incurred by moving quickly in software engineering.
相比一般的软件系统,ML系统更易带来技术负债,除了传统的软件系统维护问题之外,还有很多ML专有的问题(ML-specific issues),并且很多负债是系统层面上的,不是代码层面上的,所以传统的通过优化代码来减轻负债的方法是不够的
ML模型的黑盒化严重,容易导致大量的含有固定假设/写死的东西的胶水代码或适配校准模块
ML packages may be treated as black boxes, resulting in large masses of “glue code” or calibration layers that can lock in assumptions.
纠缠问题(entanglement),CACE principle: Changing Anything Changes Everything 牵一发动全身;输入n维特征,其中1维的数据分布变化会导致其他n-1维特征的权重变化;增加特征也是类似的问题;移除特征也是类似的问题;除了输入信号(input signals)以外,超参数、配置、抽样方法、收敛阈值、数据筛选等等都遵循CACE原则。
依赖负债是增加传统软件系统代码复杂度的重要原因,而对于ML系统,数据依赖是依赖当中更难发现的一种
未充分使用的数据依赖(underutilized data dependencies),还是依赖,因为不确定是否可以切断
典型的未充分使用的数据依赖
- 遗留特征(legacy features),过去试验性使用过,随着模型迭代被其他特征替代,但未移除
- 捆绑特征(bundled features),一组特征放在一起使用,但迫于ddl,未深究任一特征均有用
- 微增值特征(epsilon-features),为了极小的准确率提升而引入的性价比低的特征
- 相关特征(correlated features)
难以明晰的反馈循环会导致分析负债,即难以保证系统自身变更会从哪些方面影响自己
使用通用的类库往往会导致大量的胶水代码,后者从长期角度看是高维护成本的
Using generic packages often results in a glue code system design pattern, […]. Glue code is costly in the long term […]
胶水代码(glue code)和流水线丛林(pipeline jungles)这类集成问题的根因往往是科研和工程的分离
Glue code and pipeline jungles are symptomatic of integration issues that may have a root cause in overly separated “research” and “engineering” roles.
通过增加if-else分支可以快速地在一套基准代码上扩展出新方案并投入实验,但长此以往会遗留很多条件分支,难以维护,难以端到端回归测试,进而难以保证上到生产系统后不会有意外情况进入不该进入的分支,Kight Capital血淋淋的教训,45分钟内损失4650万美元。
应推崇研究与工程融合的文化,一碗水端平,模型层面准确率的提升应当与系统层面复杂度的降低有同等的重要性
It is important to create team cultures that reward deletion of features, reduction of complexity, improvements in reproducibility, stability, and monitoring to the same degree that improvements in accuracy are valued.
Paying down ML-related technical debt […] often only achieved by a shift in team culture. Recognizing, prioritizing, and rewarding this effort is important for the long term health of successful ML teams.
在快速发展中的ML系统团队对于减少负债和采用好实践是不自知的或不屑一顾的,但负债和代价是随时间而逐步显现的
在发展过程当中多问自己的问题:
- 以生产尺度测试一个全新的算法有多容易?
- 数据依赖的完整传导过程是什么?
- 一次变更对系统的影响可以被细致观测到什么程度?
- 改进模型或输入信号(signal)会使其他模型效果变差吗?
- 团队的新成员多久可以习得实战能力?
Maintainable ML
为了微小的准确率提升而付出大幅增加系统复杂度的代价,这种研究方案是不可取的(Reasonable ML?)