一、Finalizer简介
Finalizer是K8s资源删除流程中的一种控制机制。
在现实中,K8s中的资源往往不是完全独立和无状态的,2个资源对象之间可能会有依赖关系,随意删除一个对象可能会对依赖它的其他对象产生影响。因此,这些复杂的资源对象的删除流程也需要引入复杂的处理逻辑。
Finalizer就是服务于这类需求的一种机制,它可以在资源的删除过程中增加一个步骤,为这类复杂的删除逻辑的实现提供了可能。
举一个不太严格的例子,这里我们可以类比RDBMS里的外键:book表的作者字段外键关联到writer表。当我们不定义外键的ON DELETE逻辑时,一个writer条目是无法先于他/她的著作books被删除的。我们有至少两种处理writer deletion的方式:(1)定义外键ON DELETE,可以是CASCADE、SET NULL等等;(2)在外部系统中实现先删除books再删除writer的逻辑。两种处理方式的根本思想都是,在切实地删除writer之前,先“清理干净”它的依赖关系。Finalizer就可以想象成这个“清理”操作的插槽。
再举一个不太严格的例子,我们还可以类比很多面向对象的编程框架中的对象生命周期钩子(hook),比如Android框架中Activity的onDestroy和Vue框架中的beforeDestroy,在一个对象即将被删除之前,调用一个通过钩子函数/方法/扩展插槽定义的一套处理逻辑。Finalizer也可以想象成这种钩子插槽。
二、Finalizer原理
实际上,Finalizer的原理非常简单优雅,它在K8s对象上的存在形式其实是一系列标签,类似annotations。它本身并不定义流程细节或实现具体逻辑。K8s在接收到一个资源对象删除请求时,会先在对象上打上一些标记,包括deletionTimestamp,表示该对象已进入删除流程,当检测到对象上有finalizers标签(通常在资源对象的metadata字段中)时,删除流程会被挂起,直到所有finalizers标签被移除时,才继续进行删除流程(后面还会经历其他类似的阶段,例如ownerRefenreces,最终才会实际删除对象),如下图所示:
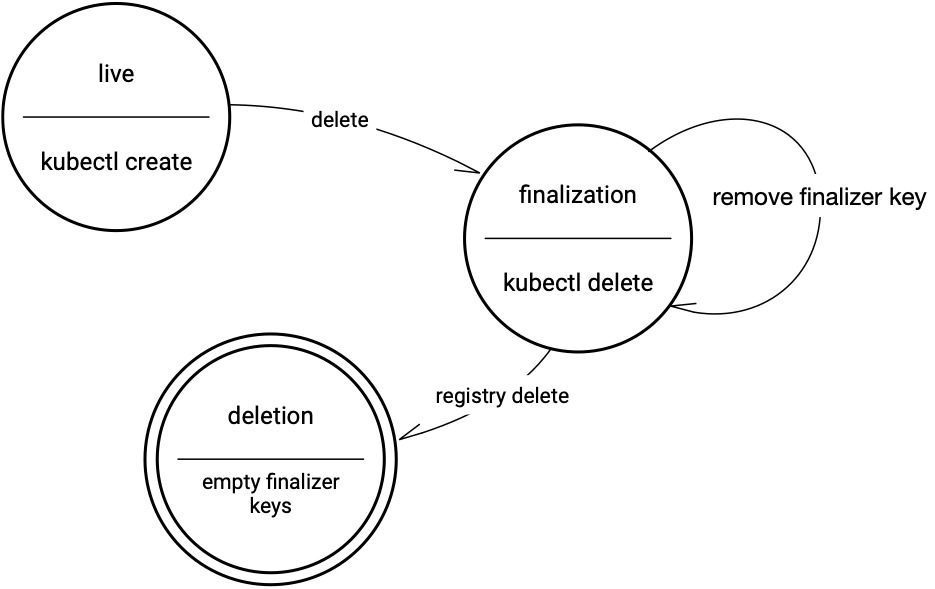
(Finalization状态转移图,引自:https://kubernetes.io/blog/2021/05/14/using-finalizers-to-control-deletion/)
在删除流程因finalizers标签被挂起时,对象控制器(controller-manager)通过对finalizer标签的捕获,可以得知这里可能有在删除对象之前需要处理的事情,再由控制器或其他组件/控制器实际去处理这些事情。当控制器认为所有该处理的事情都处理得当的时候,控制器来移除finalizers标签,从而将删除流程进行下去,直到最终实际删除掉对象。处理finalizers的思路是很开阔的:可以是主动地由本对象的controller来直接处理相关的清理工作,也可以是被动地等待外部组件或其他对象的控制器去完成它们的工作。
三、K8s原生Finalizer示例
K8s的一些原生资源对象会自动被加上一些finalizers。由于这些对象的控制器也是原生的,在不做扩展的情况下,这些原生的finalizers都是被定义好的,不应随意添加不被原生控制器识别的finalizers,避免无法删除对象的问题。
PVC和PV分别原生自带
kubernetes.io/pvc-protection和kubernetes.io/pv-protection的finalizers标签的,顾名思义,其目的在于保护持久化存储不被误删,避免挂载了存储的工作负载产生问题。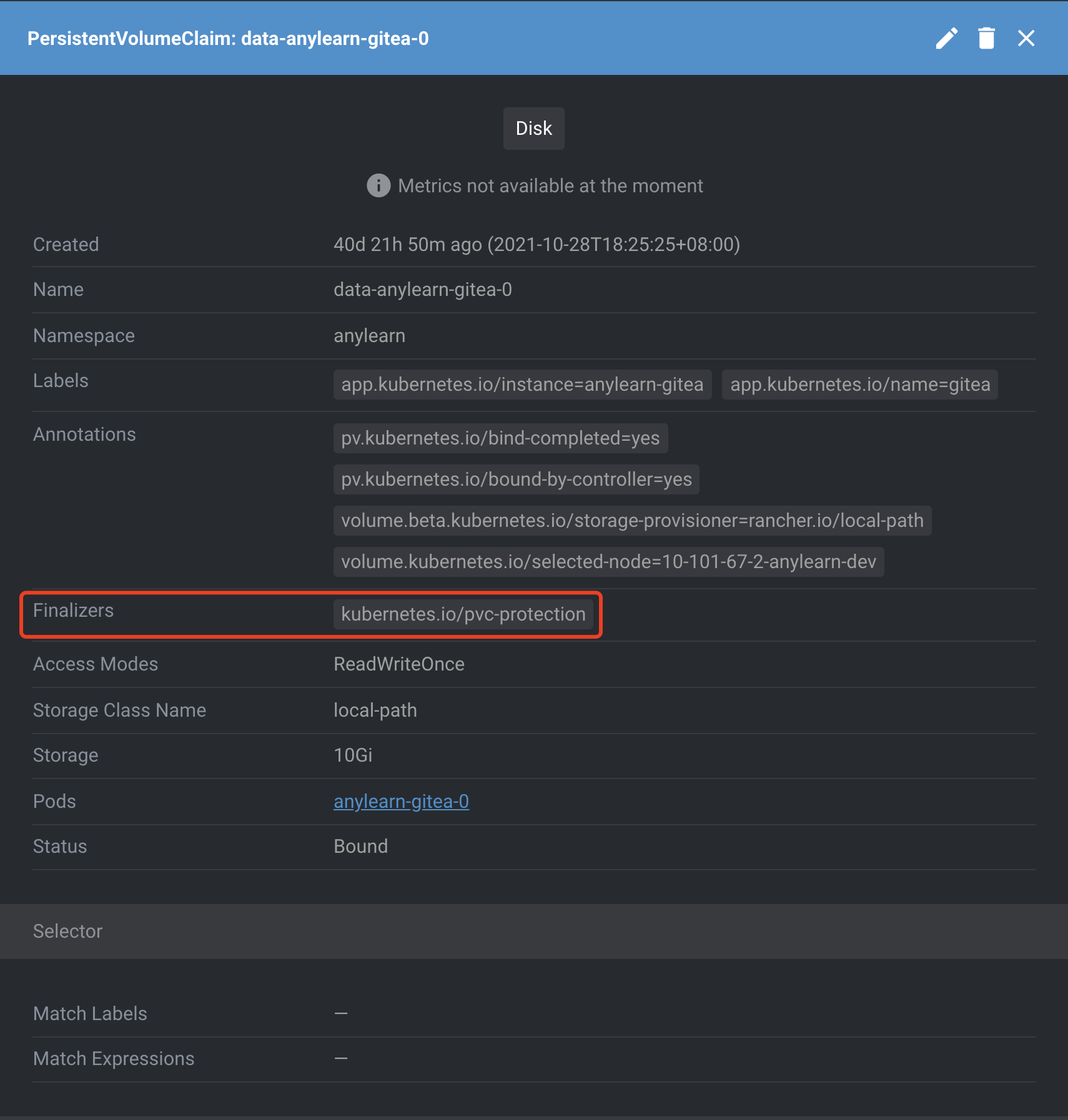
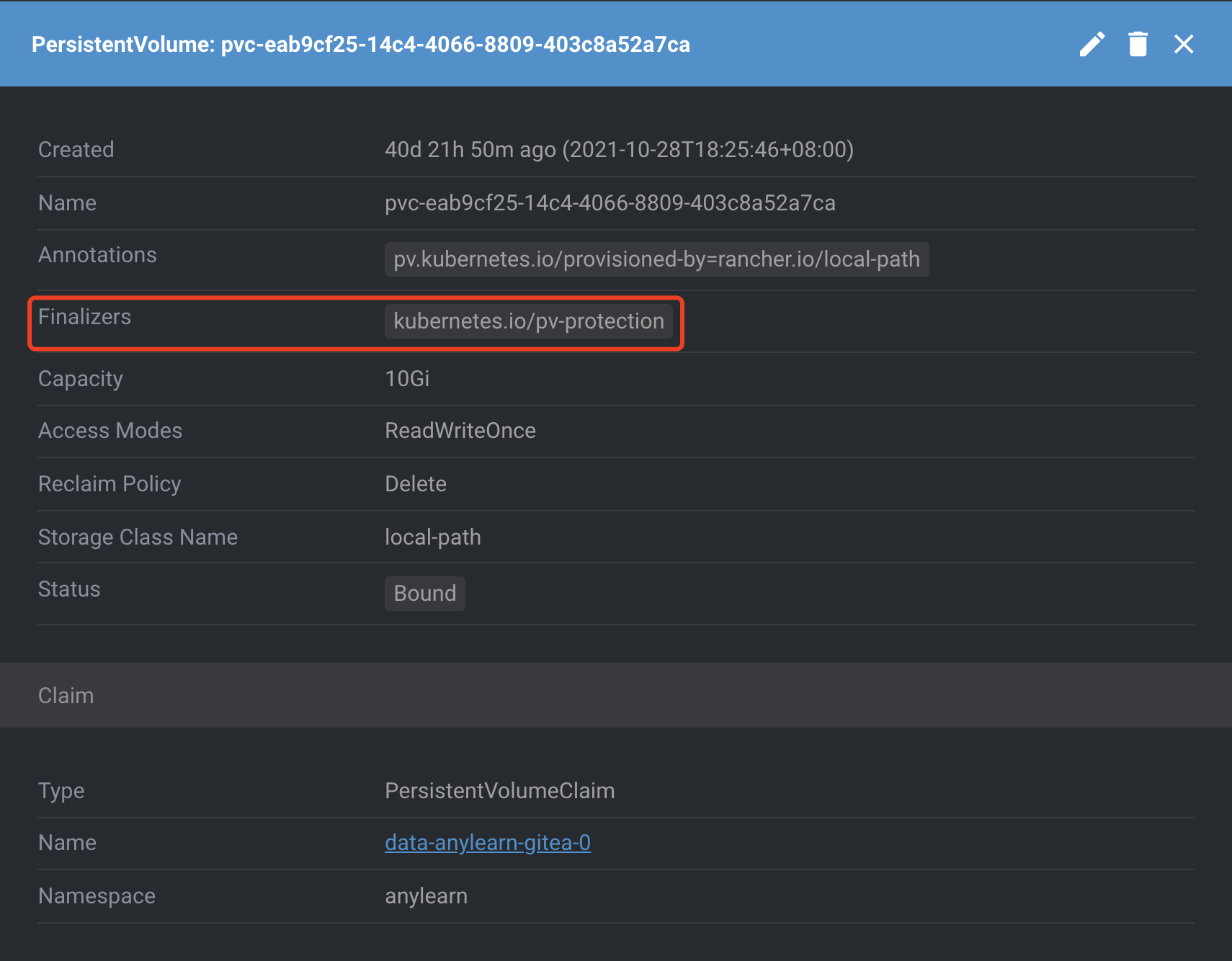
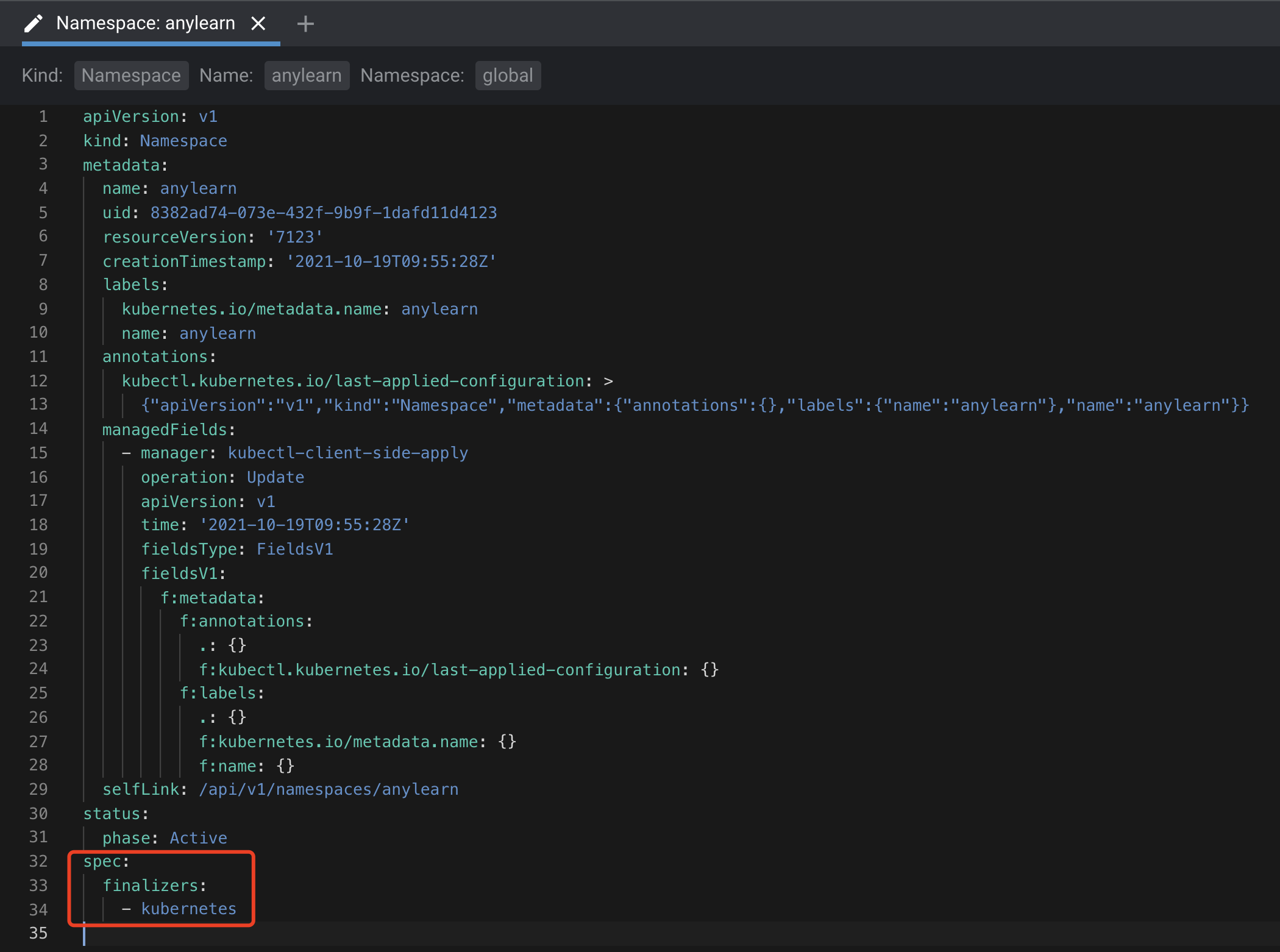
Namespace也是自带一个kubernetes的finalizers标签的,只不过,不同于其他资源对象的metadata.finalizers标签,ns是spec.finalizers,其作用是相同的。
四、某系统中的Finalizer实践
类似Pod-PVC-PV的挂载依赖关系,实际工作的某系统当中的后端组件(以CRD进行了抽象,称Backend)与自研存储(亦以CRD进行了抽象,称Cave)之间也有这层挂载依赖。在日常的开发调试以及部署时的蓝绿、红黑、灰度等过程中,经常要对后端组件进行卸载重装。如果在卸载时,先删除了Cave的话,那么挂载了它的后端容器便无法优雅删除。这是因为Cave本质是基于NFS的文件存储,而NFS的设计是在客户端unmount阶段中依然需要NFS服务端进行响应,若Cave已删除,则相当于NFS服务端失去响应,那么客户端的unmount操作会一直被挂起。
不止于此,由于Kubelet是处理工作负载的总控制程序,unmount这个操作也是由它去实际执行的,unmount的挂起也造成Kubelet处理unmount的子进程被挂起,从而导致Kubelet本身也无法再优雅停止。当然,这并不会造成集群系统的不可用,但当我们需要重启Kubelet时,就会造成Kubelet与集群失联。这也是之前某次生产集群开启Feature Gates时真实遇到的问题(因需要重启Kubelet)。比较straightforward的解决方法就是重启大法……但可想而知,这会对集群的可用性产生影响。
因此,我们应当确保在删除一个Cave组件之前,挂载了它的后端工作负载均已被删除。这个思想与pv-protection如出一辙。
我们之前已有Operator实现了Cave的控制器,Cave的Finalizer机制便是在Cave控制器的调谐方法中进行扩展的。
1 | caveProtectionFinalizer := "abc/cave-protection" |
可以看到,我们在调谐Cave时,首先要确保当一个Cave未被请求删除时,即deletionTimestamp为空时,用来保护Cave不先于后端被删除的Finalizer要加装到Cave对象上(升级考虑,旧系统已部署的Cave未采用Finalizer,而更新升级时我们不希望卸载重装Cave)。再来,当Cave已被请求删除时,判断finalizers标签是否存在,如果不存在则说明该Cave删除前的清理工作已处理完成,可以正常删除,便就此跳出调谐,交由K8s接管真正的Cave删除工作。若finalizers仍存在,则说明上一次调谐过后,还存在有与此Cave对象有挂载关系的后端pod,那么这里再重新list出所有后端pods,并计算出与此Cave对象有挂载关系的后端pods的数量(具体条件在本系统中由挂载卷名称name和挂载属性nfs.server共同决定):若数量为零,则移除finalizers并跳出调谐,交由K8s接管Cave的删除;若数量不为零,则强制安排间隔一段时间后的下一次调谐,以期在稍后的调谐时后端可以被清理干净。