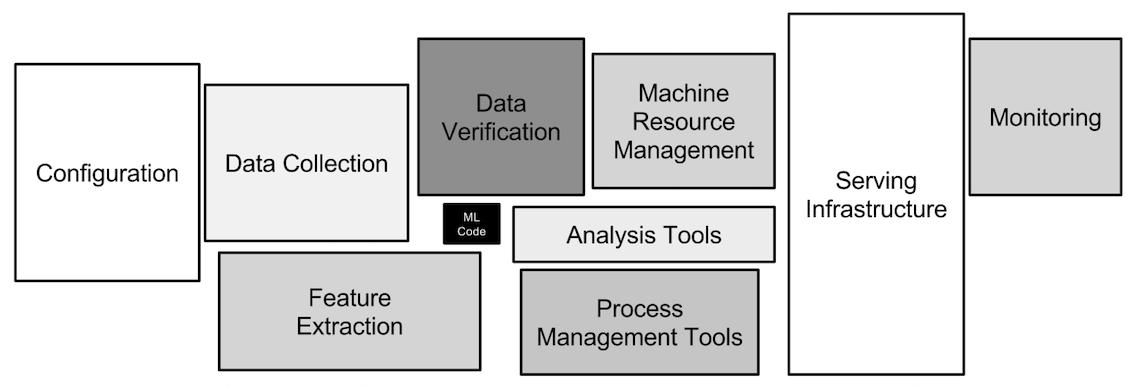
使用ML来支撑业务系统并不像看上去那么速赢(quick win),它往往会带来高昂的后期维护开销。本文旨在警示ML从业者(increase the community’s awareness),从技术负债的角度,论述了在做ML系统设计时需要注意的容易产生负债的几个方面:系统边界、耦合、反馈循环、消费者、数据依赖、配置问题等等。
二、内容
三、Key takeaways
令人不安的趋势:开发和部署ML系统很快很便宜,但后期维护它们既难且贵
[…] a wide-spread and uncomfortable trend […] : developing and deploying ML systems is relatively fast and cheap, but maintaining them over time is difficult and expensive.
Not all debt is bad, but all debt needs to be serviced.
Technical debt may be paid down by refactoring code, improving unit tests, […]. The goal is not to add new functionality, but to enable future improvements, reduce errors, and improve maintainability.
在系统设计时考虑技术负债能够提前认识到加速工程落地会为系统维护带来的长期开销
[…] help reason about the long term costs incurred by moving quickly in software engineering.
Glue code and pipeline jungles are symptomatic of integration issues that may have a root cause in overly separated “research” and “engineering” roles.
It is important to create team cultures that reward deletion of features, reduction of complexity, improvements in reproducibility, stability, and monitoring to the same degree that improvements in accuracy are valued.
Paying down ML-related technical debt […] often only achieved by a shift in team culture. Recognizing, prioritizing, and rewarding this effort is important for the long term health of successful ML teams.
Given the vagaries of large-scale trace data collection, we found that most of these invariants were violated occasionally. […] Automated validation […] one-off scripts to a repeatable pipeline […] In retrosepct, we should have started with that […]
4. 可解释的调度是研究方向
两方面好处:(1)面向运维,可以明晰集群的整体运行状态;(2)面向用户,可以有指导性作用。
It would be nice to be able to provide explanations for why the scheduler made the decisions it made - either to help system operators understand what is going on (or is about to), or to provide guidance to end users on how they could better use the cluster.
四、引申
Borg2019数据集:J. Wilkes. Google cluster-usage traces v3. Technical report at https: //github.com/google/cluster-data, Google, Mountain View, CA, USA, Nov. 2019.
阿里的数据集:Alibaba cluster data: using 270 GB of open source data to understand Alibaba data centers. Blog post, url = https://www.alibabacloud.com/blog/594340, Jan. 2019.
Borg2011数据集的分析:E. Cortez, A. Bonde, A. Muzio, M. Russinovich, M. Fontoura, and R. Bianchini. Resource central: Understanding and predicting work- loads for improved resource management in large cloud platforms. In 26th Symposium on Operating Systems Principles (SOSP), pages 153–167, Shanghai, China, 2017. ACM.
做分布式锁(本文中提到选主相关应用)的Chubby: Burrows, M. 2006. The Chubby lock service for loosely coupled distributed systems. Symposium on Operating System Design and Implementation (OSDI), Seattle, WA.
Alloc in Borg: app + logsaver + dataloader 模式,分段开发维护
Pod in K8s: init containers + helper containers/sidecars
运维的可观测辅助
Debugging information
Events
Master即内核——Borgmaster in Borg = kube-apiserver in K8s
四、同类系统
SysName
Ref
Apache Mesos
B. Hindman, A. Konwinski, M. Zaharia, A. Ghodsi,A. Joseph, R. Katz, S. Shenker, and I. Stoica.Mesos: aplatform for fine-grained resource sharing in the data center.InProc. USENIX Symp. on Networked Systems Design andImplementation (NSDI), 2011
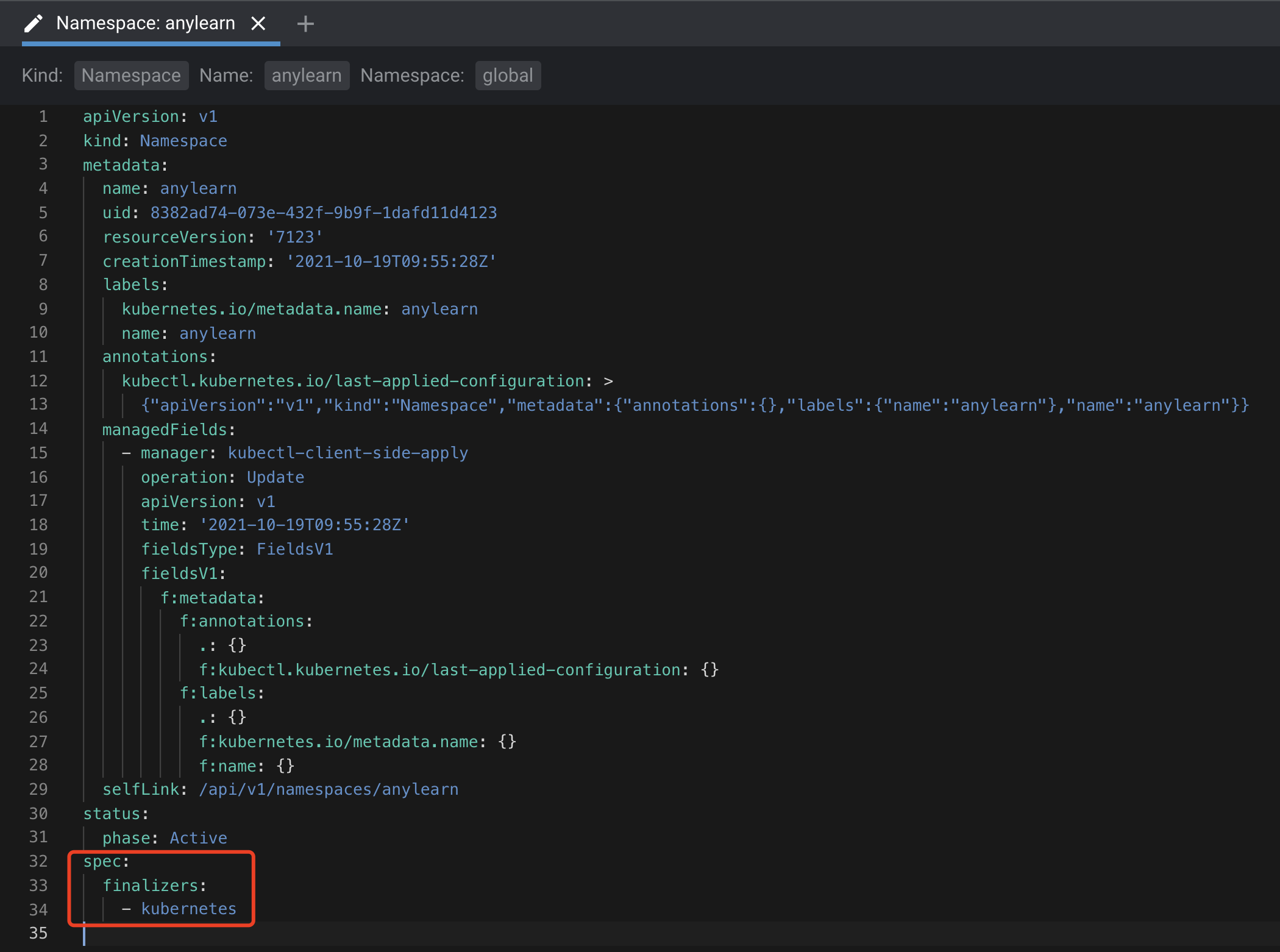
YARN
V. K. Vavilapalli, A. C. Murthy, C. Douglas, S. Agarwal,M. Konar, R. Evans, T. Graves, J. Lowe, H. Shah, S. Seth,B. Saha, C. Curino, O. O’Malley, S. Radia, B. Reed, andE. Baldeschwieler.Apache Hadoop YARN: Yet AnotherResource Negotiator.InProc. ACM Symp. on CloudComputing (SoCC), Santa Clara, CA, USA, 2013.
M. Isard, V. Prabhakaran, J. Currey, U. Wieder, K. Talwar,and A. Goldberg.Quincy: fair scheduling for distributedcomputing clusters.InProc. ACM Symp. on OperatingSystems Principles (SOSP), 2009.
E. Boutin, J. Ekanayake, W. Lin, B. Shi, J. Zhou, Z. Qian,M. Wu, and L. Zhou.Apollo: scalable and coordinatedscheduling for cloud-scale computing.InProc. USENIXSymp. on Operating Systems Design and Implementation(OSDI), Oct. 2014.
Fuxi
Z. Zhang, C. Li, Y. Tao, R. Yang, H. Tang, and J. Xu.Fuxi: afault-tolerant resource management and job schedulingsystem at internet scale.InProc. Int’l Conf. on Very LargeData Bases (VLDB), pages 1393–1404. VLDB EndowmentInc., Sept. 2014.
Omega
M. Schwarzkopf, A. Konwinski, M. Abd-El-Malek, andJ. Wilkes.Omega: flexible, scalable schedulers for largecompute clusters.InProc. European Conf. on ComputerSystems (EuroSys), Prague, Czech Republic, 2013.
大规模系统的关键因素:J. Hamilton.On designing and deploying internet-scaleservices.InProc. Large Installation System AdministrationConf. (LISA), pages 231–242, Dallas, TX, USA, Nov. 2007.
系统性能评测的建模:D. G. Feitelson.Workload Modeling for Computer SystemsPerformance Evaluation.Cambridge University Press, 2014.
资源利用率相关指标和实验:A. Verma, M. Korupolu, and J. Wilkes.Evaluating jobpacking in warehouse-scale computing.InIEEE Cluster,pages 48–56, Madrid, Spain, Sept. 2014.
资源调度worst-fit:Y. Amir, B. Awerbuch, A. Barak, R. S. Borgstrom, andA. Keren.An opportunity cost approach for job assignmentin a scalable computing cluster.IEEE Trans. Parallel Distrib.Syst., 11(7):760–768, July 2000.
数据集分析:C. Reiss, A. Tumanov, G. Ganger, R. Katz, and M. Kozuch.Heterogeneity and dynamicity of clouds at scale: Googletrace analysis.InProc. ACM Symp. on Cloud Computing(SoCC), San Jose, CA, USA, Oct. 2012.
使用:O. A. Abdul-Rahman and K. Aida.Towards understandingthe usage behavior of Google cloud users: the mice andelephants phenomenon.InProc. IEEE Int’l Conf. on CloudComputing Technology and Science (CloudCom), pages272–277, Singapore, Dec. 2014.
使用:S. Di, D. Kondo, and W. Cirne.Characterization andcomparison of cloud versus Grid workloads.InInternationalConference on Cluster Computing (IEEE CLUSTER), pages230–238, Beijing, China, Sept. 2012.
使用:S. Di, D. Kondo, and C. Franck.Characterizing cloudapplications on a Google data center.InProc. Int’l Conf. onParallel Processing (ICPP), Lyon, France, Oct. 2013.
使用:Z. Liu and S. Cho.Characterizing machines and workloadson a Google cluster.InProc. Int’l Workshop on Schedulingand Resource Management for Parallel and DistributedSystems (SRMPDS), Pittsburgh, PA, USA, Sept. 2012.
Usage: rsync [OPTION]... SRC [SRC]... DEST or rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST or rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST or rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST or rsync [OPTION]... [USER@]HOST:SRC [DEST] or rsync [OPTION]... [USER@]HOST::SRC [DEST] or rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST] The ':' usages connect via remote shell, while '::' & 'rsync://' usages connect to an rsync daemon, and require SRC or DEST to start with a module name.
在做目录级的传输时,需要特别注意的是,源目录路径末尾有没有斜杠是会有不同效果的:
带斜杠,如/data/,则同步/data目录下的所有文件到目标路径下
不带斜杠,如/data,则同步/data目录到目标路径下,作为子目录
一些有用的options
-a 全家桶选项,组合了多个其他选项(-rlptgoD),基本无脑使用,并且对于目录来说-a是包含-r的
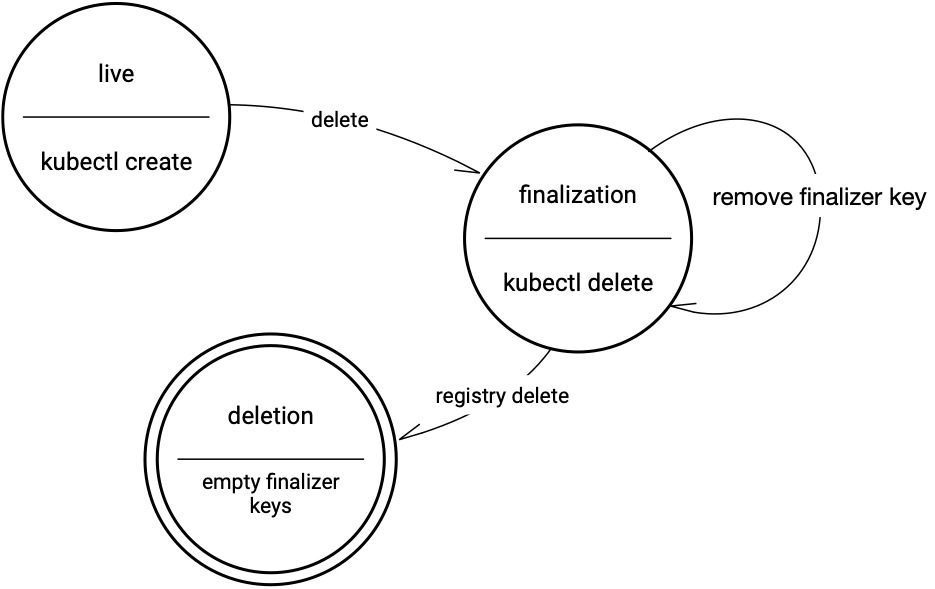
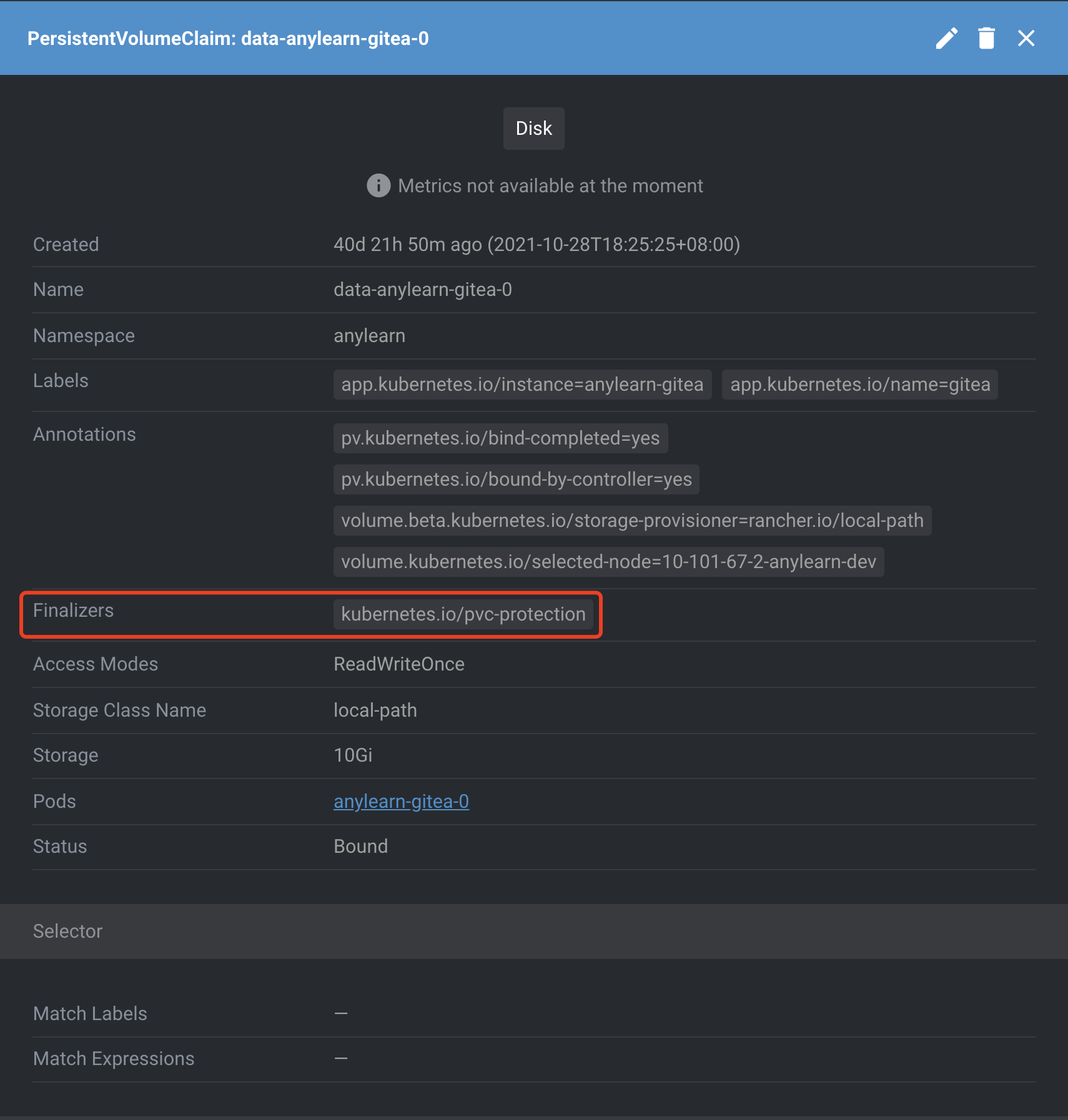
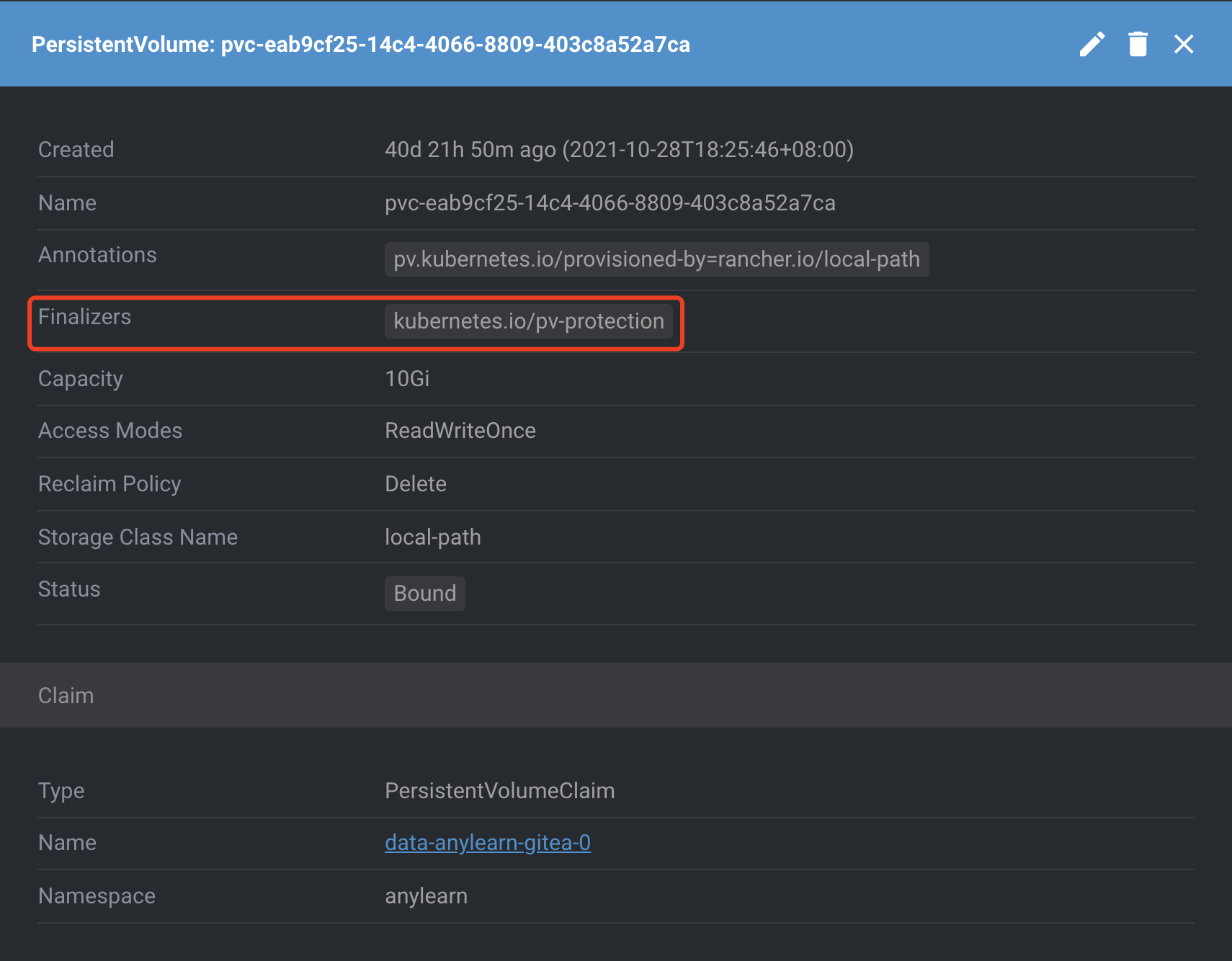
if cave.ObjectMeta.DeletionTimestamp.IsZero() { // Cave is not being deleted: // append finalizer to protect cave from being deleted before backend & hpo // otherwise backend & hpo might fail to unmount cave // which make kubelet hang if !containsFinalizer(cave.GetFinalizers(), caveProtectionFinalizer) { controllerutil.AddFinalizer(&cave, caveProtectionFinalizer) if err := r.Update(ctx, &cave); err != nil { reqLogger.Error(err, "unable to add finalizer on cave resource", "cave", cave.Name) } return ctrl.Result{Requeue: true}, nil } } else { reqLogger.Info("got deletion request", "cave", cave.Name) // Cave is being deleted: // the deletion should be pending until backend pods are terminated if containsFinalizer(cave.GetFinalizers(), caveProtectionFinalizer) { // List backend pods var backendPods v1.PodList if err := r.List(ctx, &backendPods, client.InNamespace(req.Namespace), client.MatchingLabels{"app": "anylearn-backend"}); err != nil { reqLogger.Error(err, "unable to list backend pods") return ctrl.Result{}, err } // Count pods using current cave nbOccupants := 0 for _, pod := range backendPods { for _, v := range pod.Spec.Volumes { if v.Name == cave.Name && v.NFS.Server == cave.Status.ServiceIP { nbOccupants++ reqLogger.Info("Pod still using cave", pod.Name, cave.Name) } } } // Remove finalizer if backend pods are gone so that cave deletion can be truely proceeded if nbOccupants == 0 { controllerutil.RemoveFinalizer(&cave, caveProtectionFinalizer) if err := r.Update(ctx, &cave); err != nil { reqLogger.Error(err, "unable to remove protection finalizer from cave resource", "cave", cave.Name) return ctrl.Result{Requeue: true}, err } // End of reconcilation return ctrl.Result{}, nil } else { // Still got some pods using this cave, requeue the reconcilation return ctrl.Result{Requeue: true, RequeueAfter: 20 * time.Second}, nil } } }
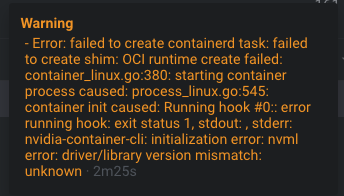
装完驱动后,再用cuda11.4的runfile装cuda,安装时去掉自带的470驱动安装,仅安装cuda。这样安装完后就是460驱动的k40c/k40m+cuda11.4了。但是这样装完,daemon-reload或重启之后,nvidia-smi会报driver/library version mismatch。可能还是需要装cuda11.2才能完美匹配。